
Smart Data: Union Investment beschäftigt ein Team von Datenspezialisten, um Investments noch umfassender bewerten zu können. Das kommt auch den Kunden der Volksbanken und Raiffeisenbanken zu Gute.
Anzeige


Anzeige
„Daten sind das neue Öl“ – den Spruch kann nun wirklich keiner mehr hören. Nicht nur ist dieser fragwürdige Vergleich übermäßig viel gebraucht worden, sondern er hinkt obendrein noch: Eine Ölquelle lässt sich gut erschließen, da das Know-how und die Technik dazu seit mehr als 100 Jahren perfektioniert wurden. Die Infrastruktur besteht, für sämtliche Verarbeitungsschritte und Nebenprodukte gibt es Experten und Abnehmer.
Finde ich heute aber in meinem Unternehmen einen über die Jahre gewachsenen „Datentopf“, kann ich nicht einfach auf bewährte Verarbeitungsketten zurückgreifen. Allzu häufig sitzen Entscheider in Unternehmen deswegen vor einer zentralen Frage: Hier habe ich vermeintlich wertvolle Daten – und jetzt?
Ungenutzte Datenvielfalt
Freilich haben einige Anbieter dieses Problem längst gelöst. Mit Google und Facebook sind zwei der weltweit größten Unternehmen nur aufgrund des schieren Werts von Kundendaten in ihre jetzige Position gekommen. Da wundert es auch nicht, dass beide Firmen versuchen, ihren bereits immensen Datenschatz mit Informationen aus weiteren Quellen anzureichern. So hat Google laut Medienberichten in den USA im vergangenen Jahr massenhaft Kreditkarten-Transaktionsdaten von Mastercard gekauft. Auch Facebook soll bei US-amerikanischen Großbanken nach Kooperationsmöglichkeiten gefragt haben.
Wieso begeben sich diese zwei Technologie-Riesen in seichtes Gewässer, um an Bankdaten zu kommen? Weiß Google nicht schon, wo ich meinen nächsten Urlaub verbringen werde? Kann Facebook nicht bereits akkurat aufgrund weniger Likes meine Persönlichkeitsstruktur bestimmen? Schon – aber die Banken wissen noch weitaus mehr. Zumindest könnten sie es wissen.
Aus Transaktionsdaten lässt sich selbst mit simplen Methoden eine Vielzahl an interessanten Einblicken gewinnen. Selbstverständlich sind Einkaufsverhalten und -vorlieben einfach bestimmbar, doch ebenfalls können mithilfe der Adressen von Läden und Restaurants Bewegungsprofile erstellt werden. Durch die Höhe des Kindergelds lassen sich Rückschlüsse auf die Anzahl der Kinder ziehen – bei langfristig genutzten Konten auch deren Alter. Tankkosten zeigen gefahrene Kilometer an; die Schätzung kann durch Höhe der KFZ-Steuer sogar noch genauer werden.
Ein komplizierter Ausweg
Moderne Algorithmen sind also in der Lage, durch sogenanntes „Deep Learning" Rückschlüsse aus scheinbar belanglosen Daten zu ziehen. Dem einen oder anderen mag das zu weit gehen. Denn in kaum einem Geschäftsfeld ist Vertrauen ein dermaßen wertvolles und grundlegendes Gut wie bei Banken. Als Kunde vertraue ich einer Bank mein Geld an, weil es dort sicher ist. Das Gleiche erwarte ich bei meinen Daten.
Dennoch bieten diese Daten Geschäftspotenzial – eine Zwickmühle für den, der sie nutzen will. Eine Lösung, die sogar juristisch untermauert ist, stellt die Anonymisierung dar. Korrekt anonymisierte Daten sind ohne überproportionalen Aufwand nicht mehr auf Einzelpersonen rückführbar – unabhängig davon, über welche Zusatzinformationen ein Analyst verfügt. Damit können persönliche Daten sicher und legal ausgewertet werden: Die Datenschutz-Grundverordnung (DSGVO) spezifiziert in Erwägungsgrund 26 ausdrücklich: „Die Grundsätze des Datenschutzes sollten [...] nicht für anonyme Informationen gelten“.
Damit scheint alles geklärt: Muss man sich keine Sorgen mehr machen, sobald die Daten anonymisiert sind? Wenig überraschend ist es leider nicht so einfach.
Typischerweise ergeben sich in diesem Prozess drei Probleme:
- Anonymisierung ist sehr komplex und aufwendig. Es ist nicht damit getan, sogenannte Identifizierungsmerkmale (wie Namen oder Kontonummern) zu entfernen – so sind beispielsweise in den Vereinigten Staaten 63 Prozent der Bürger eindeutig durch Geburtsdatum, Geschlecht und Postleitzahl zu identifizieren. Selbst ein solch simpler Datensatz benötigt tiefgreifende Methoden der Anonymisierung, fast immer mit hohem manuellen Aufwand und schwierigen Abwägungen.
- Sollte die Anonymisierung nicht korrekt durchgeführt worden sein, entsteht ein großes Risiko für die Verantwortlichen – die DSGVO sieht für Verstöße Geldbußen von bis zu 4 Prozent des Jahresumsatzes oder 20 Millionen Euro vor.
- Sollte die Anonymisierung allerdings völlig korrekt verlaufen sein, ergibt sich ein entscheidendes weiteres Problem: Die Datenqualität leidet üblicherweise enorm. Man nehme den oben erwähnten Datensatz der US-Bürger: Selbst wenn statt der Postleitzahl nur das Herkunftsland genannt wird, sind immer noch circa 18 Prozent der Personen eindeutig identifizierbar. Man müsste also weitere „Vergröberungen“ vornehmen, wie zum Beispiel statt des Geburtsdatums nur den Geburtsmonat anzugeben. Die Nützlichkeit des Datensatzes leidet darunter sichtbar. Der Datenschutzforscher Paul Ohm schrieb daher in 2010: „Daten können entweder nützlich oder perfekt anonymisiert sein – aber niemals beides.“
Die wichtigsten Begriffe zum Datenschutz
Anonymisierung
Bei der Anonymisierung werden Daten derart verändert, dass ein Rückschluss auf natürliche Personen nicht mehr oder nur durch überproportional hohen Aufwand möglich ist. Dies wird zum Beispiel dadurch erreicht, dass Datenpunkte zu Gruppen zusammengefasst werden oder ein Rauschen – das heißt falsche Daten – zu einem Datensatz hinzugefügt werden. Anonymisierte Daten sind rechtlich gesehen unbedenklich und unterliegen nicht den Datenschutzgesetzen.
Pseudonymisierung
Bei der Pseudonymisierung werden direkte Identifikatoren eines Datensatzes mit Pseudonymen ersetzt oder gelöscht – zum Beispiel könnte eine Telefonnummer mit zufälligen Ziffern ausgetauscht werden, oder statt eines Klarnamens eine Nutzer-ID gespeichert werden. Diese Art der Verarbeitung erhält einen Großteil des Werts der Daten, ist dafür aber bei Weitem nicht so sicher wie Anonymisierung. Deswegen gelten pseudonymisierte Daten auch weiterhin als persönliche Daten im Sinne der DSGVO.
Synthetische Daten
Für synthetische Daten wird ein Machine Learning Algorithmus auf Rohdaten trainiert und erstellt dann einen neuen, „synthetischen“ Datensatz – das heißt dieser enthält nicht mehr den Inhalt der originalen Daten, aber ähnliche statistische Zusammenhänge. Synthetische Daten eignen sich besonders für Testzwecke, zum Beispiel um einen externen Entwickler eine Anwendung programmieren zu lassen, die mit der eigenen Kundendatenbank funktionieren soll, ohne ihm dafür Kundendaten zukommen lassen zu müssen.
Gewusst wie – technologische Neuerungen in der Anonymisierung
Allerdings ist das alles, wie so oft, eine Frage des Ansatzes. Als Beispiel seien die Daten genannt, die Taxis in New York City bei ihren Fahrten erzeugen. So wird zum Beispiel Start- und Zielpunkt der Fahrzeuge aufgezeichnet. Als erstes analysierte CNIL, die französische Datenschutzaufsicht, die Informationen. Die Behörde wollte demonstrieren, dass eine echte Anonymisierung dieses Datensatzes sehr wohl möglich ist. Allerdings ist das Ergebnis sehr grob und somit leider für die meisten Anwendungsfälle ungeeignet. Mit Diffix, einem Ansatz den wir bei Aircloak gemeinsam mit dem Max-Planck-Institut für Softwaresysteme entwickelt haben, lässt sich ein ebenso sicherer und doch deutlich nützlicherer Datensatz erstellen.
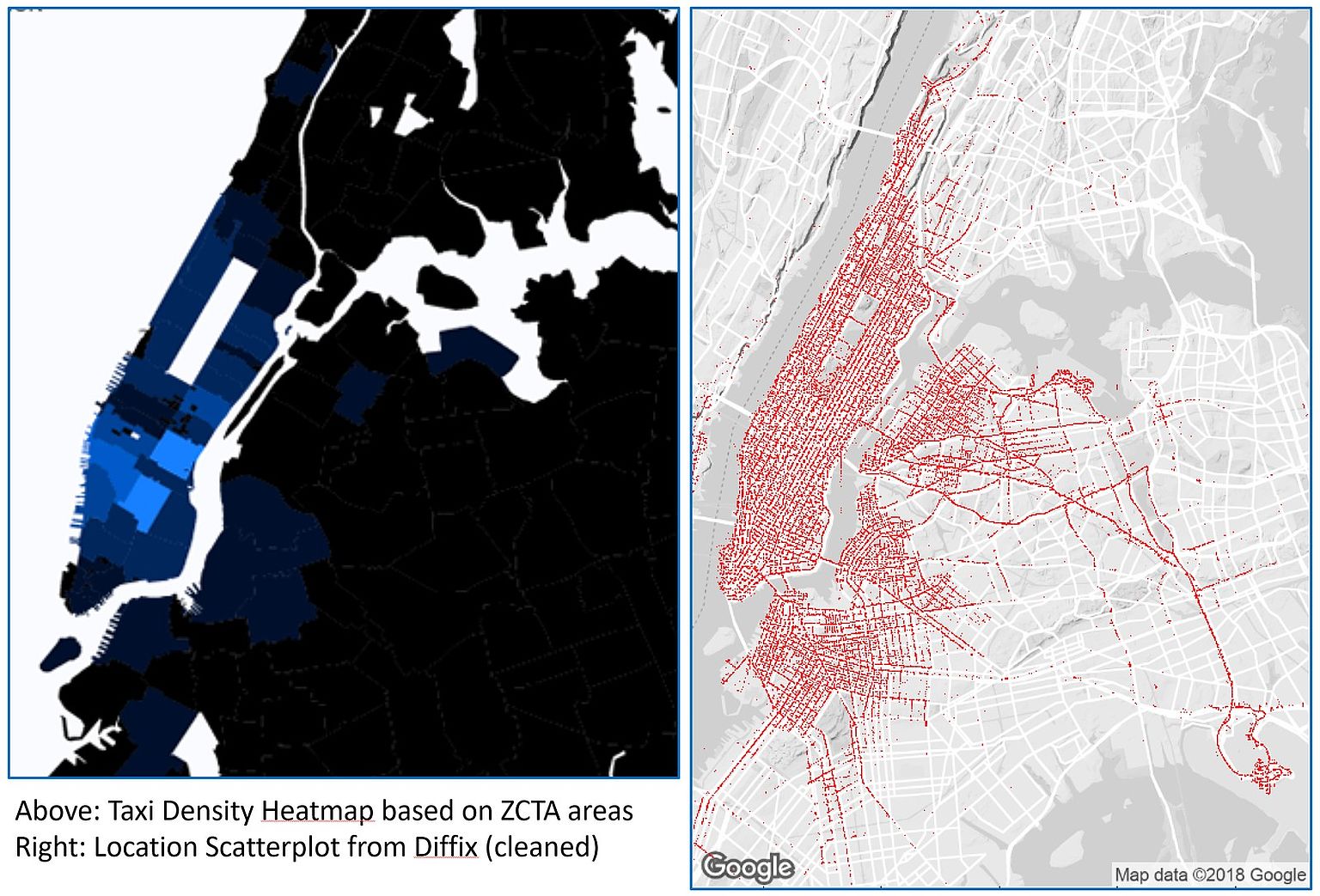
Im Gegensatz zu klassischer Anonymisierung versucht Diffix nicht, einen ganzen Datensatz am Stück abzusichern, sondern anonymisiert ihn vielmehr dynamisch bei jeder Abfrage der Datenbank ganz genau so, wie es diese Abfrage benötigt. Er gleicht also einen voll automatischen Filter zwischen Datenbank und Analysten und stellt sicher, dass Letztere zwar mit allen Datenpunkten arbeiten können, aber dies nur, ohne Rückschlüsse auf einzelne Personen zu erlauben. Somit können Datensätze schnell, einfach und sicher für neue Anwendungsfälle „entsperrt“ und trotzdem ein hohes Level an Datenschutz gewährleistet werden.
Der Ansatz wird bereits erfolgreich im Bankenwesen eingesetzt – etwa bei der TeamBank, um Transaktionsdaten anonym auszuwerten. So lässt sich zum Beispiel anhand deskriptiver Statistik feststellen, wie hoch das mittlere Einkommen einer Nutzergruppe ist. Auch Korrelationen und Regressionen sind möglich: Geben Menschen mit höherem Einkommen für Versicherungen mehr aus? Wann beantragen Menschen einen Kredit oder an welchem Wochentag kaufen sie ein? Auch jenseits des Bankensektors, etwa im medizinischen Umfeld, können Daten genutzt werden, zum Beispiel um per Smartphone gesammelte Daten von Parkinsonpatienten zu anonymisieren.
Während klassische Anonymisierung schwer zu handhaben ist und oft nicht die gewünschten Ergebnisse bringt, können moderne Technologien und Produkte sehr wohl eine Lösung darstellen. Nicht zuletzt hat die DSGVO den Markt nun auch so interessant gemacht, dass in den nächsten Jahren aller Voraussicht nach eine größere Auswahl von Produkten von verschiedenen Anbietern zu erwarten ist.
Datenschatz trotz Datenschutz
Ob Daten und Öl nun gleichzusetzen sind oder nicht: Ein Unternehmen sollte neue datengetriebene Geschäftsmodelle und -prozesse entwickeln, wenn es wettbewerbsfähig bleiben will. Moderner Datenschutz ist dabei nicht nur Voraussetzung, sondern kann sogar helfen, diese besonders wirtschaftlich und sicher zu gestalten.

Felix Bauer ist geschäftsführender Vorstand des 2014 gegründeten Unternehmens Aircloak.

